No - why?
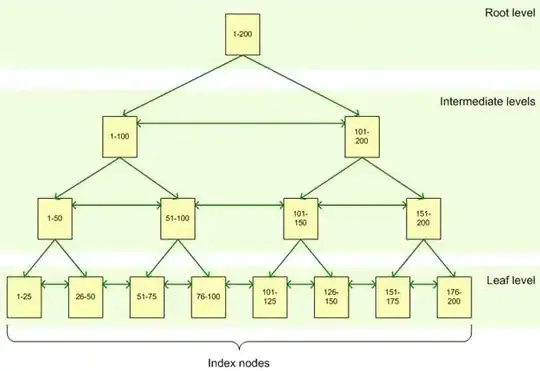
The clustered index will still store the actual data pages at its leaf level, (initially) physically sorted by the name column.
The index navigation structure above the leaf level will contain the name column values for all rows.
So overall: nothing changes.
The primary key is a logical construct, designed to uniquely identify each row in your table. That's why it has to be unique and non-null.
The clustering index is a physical construct that will (initially) phyiscally sort your data by the clustering key and arrange the SQL Server pages accordingly.
While in SQL Server, the primary is used by default as the clustering key, the two do not have to fall together - nor does one have to exist with the other. You can have a table with a non-clustered primary key, or a clustered table without primary key. Both is possible. Whether it's sensible to have that is another discussion - but it's technically possible.
Update: if your primary key is your clustering key, uniqueness is guaranteed (since the primary key must be unique). If you're choosing some column that is not the primary key as your clustering key, and that column does not guarantee uniqueness, SQL Server will - behind the scenes - add a 4-byte (INT) uniqueifier column to those duplicates values to make them unique. So you might have Smith, Smith1, Smith2 and so forth in your clustered index navigation structure for your Smith's.
See: