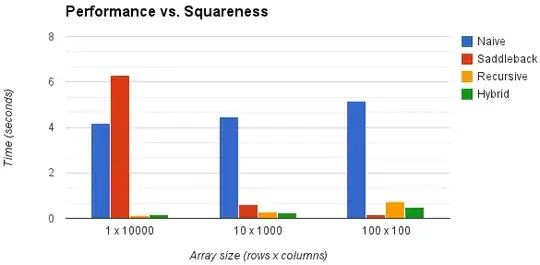
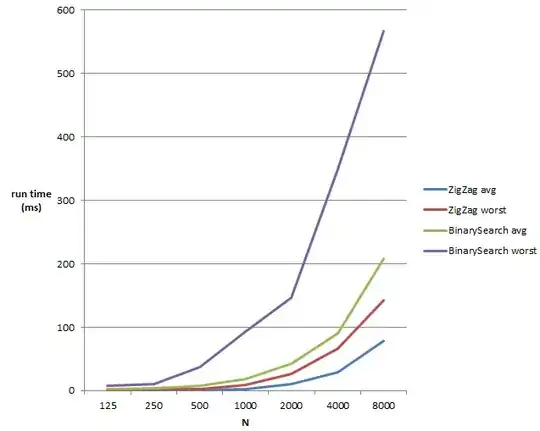
Well, to begin with, let us assume we are using a square.
1 2 3
2 3 4
3 4 5
1. Searching a square
I would use a binary search on the diagonal. The goal is the locate the smaller number that is not strictly lower than the target number.
Say I am looking for 4 for example, then I would end up locating 5 at (2,2).
Then, I am assured that if 4 is in the table, it is at a position either (x,2) or (2,x) with x in [0,2]. Well, that's just 2 binary searches.
The complexity is not daunting: O(log(N)) (3 binary searches on ranges of length N)
2. Searching a rectangle, naive approach
Of course, it gets a bit more complicated when N and M differ (with a rectangle), consider this degenerate case:
1 2 3 4 5 6 7 8
2 3 4 5 6 7 8 9
10 11 12 13 14 15 16 17
And let's say I am looking for 9... The diagonal approach is still good, but the definition of diagonal changes. Here my diagonal is [1, (5 or 6), 17]. Let's say I picked up [1,5,17], then I know that if 9 is in the table it is either in the subpart:
5 6 7 8
6 7 8 9
10 11 12 13 14 15 16
This gives us 2 rectangles:
5 6 7 8 10 11 12 13 14 15 16
6 7 8 9
So we can recurse! probably beginning by the one with less elements (though in this case it kills us).
I should point that if one of the dimensions is less than 3, we cannot apply the diagonal methods and must use a binary search. Here it would mean:
- Apply binary search on
10 11 12 13 14 15 16, not found
- Apply binary search on
5 6 7 8, not found
- Apply binary search on
6 7 8 9, not found
It's tricky because to get good performance you might want to differentiate between several cases, depending on the general shape....
3. Searching a rectangle, brutal approach
It would be much easier if we dealt with a square... so let's just square things up.
1 2 3 4 5 6 7 8
2 3 4 5 6 7 8 9
10 11 12 13 14 15 16 17
17 . . . . . . 17
. .
. .
. .
17 . . . . . . 17
We now have a square.
Of course, we will probably NOT actually create those rows, we could simply emulate them.
def get(x,y):
if x < N and y < M: return table[x][y]
else: return table[N-1][M-1] # the max
so it behaves like a square without occupying more memory (at the cost of speed, probably, depending on cache... oh well :p)