in SQL Server Management Studio (SSMS) 2008 R2 Dev on the table (because I cannot ask without it)
--SET ANSI_NULL_DFLT_ON ON
create table B (Id int)
I create unique constraint
ALTER TABLE B
ADD CONSTRAINT IX_B
UNIQUE (ID)
WITH (IGNORE_DUP_KEY = ON)
SSMS shows that I do not have any constraint but have a key + index instead while context options (on right clicking) hint me to create (sorry, script) still constraint.
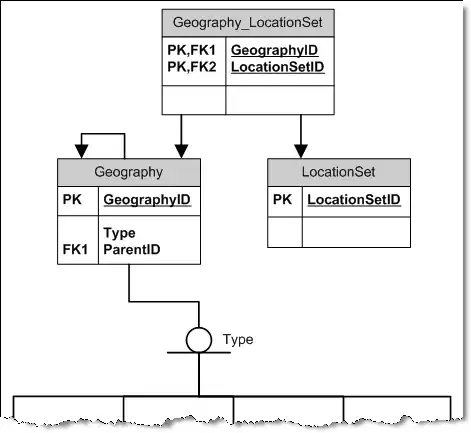
MAIN QUESTION:
What is a key here?
Why is it needed for this constraint?
Why is unique constraint called by key (and key by unique constraint)?
Sorry, again, why is key called by index? They seem to have the same name (though had I created without explicit name they would have called differently)...
Sorry, again...
COLLATERAL questions:
Which functionality is different between "unique constraint" vs. "unique index"? I searched today for a single difference (wanted to find 10) quite a time and could not find any.
In other words, what's for (why) are concepts (or constructs) "unique constraint" and "unique index" are duplicated in SQL Server?
Bonus question (for those whom this question seemed too simple):
What is the sense in unique index (or in unique constraint) permitting dupes?
insert into B VALUES (1)
insert into B VALUES (1)
insert into B VALUES (1)
Update: Sorry Thanks, guys and ladies (bonus is withdrawn)
Update2: Was not there a difference between "unique index" and "unique constraint" in previous SQL Server (I vaguely recall that one of them did not permit NULL)?
Update3: Really, I was always pissed off (confused) by a "foreign key constraint" is called by "foreign key" while it is not a key and the key, foreign one is in another table, foreign one ... and just found that this is universal confusion to rattle on it. At least, now I memorize that I should remember au contraire.
Update4:
@Damien_The_Unbeliever, thanks,
these are, at least, some hrooks to memorize confusion.
Though, some bewilderments:
Why are these candidates NOT NULL by default?
Initially I really wanted to insert much shorter script:
CREATE TABLE A(A INT UNIQUE);
which produced:
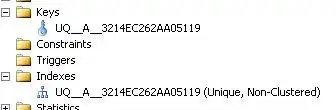
WTF this "candidate" for PRIMARY and KEY has multiple identities syndrome, then?
Is not "UQ_" stand for Unique constraint in naming practices?
Now, scripting of this index UQ__A__3214EC262AA05119 produces nameless... not index ... constraint(?!):
ALTER TABLE [dbo].[A] ADD UNIQUE NONCLUSTERED
(
[ID] ASC
)
WITH
( PAD_INDEX = OFF,
STATISTICS_NORECOMPUTE = OFF,
SORT_IN_TEMPDB = OFF,
IGNORE_DUP_KEY = OFF,
ONLINE = OFF,
ALLOW_ROW_LOCKS = ON,
ALLOW_PAGE_LOCKS = ON)
ON
[PRIMARY]
WTheF - How is unique index is identified as constraint? Where, by what
Scripting of key produces the same! again, constraint...
Why is it nameless? Why is it impossible to script as "modify" but only as "create"?!
This does not make sense!
Now if to execute the produced script, there are 2 dupes,
to execute once more - voila: 3 dupe "candidates"

Note: if to create the unique constraint by separate T-SQL statement with custom/manual name, as I made at the top, then scripting does not produce anonymous DML and, respectively, their execution does not permit multiplication of "candidates"
Strange candidates for primary keys, aren't they? need to visit a shrink (with multiple identities symptoms)?